Design tokens automation pipeline: From design tools to component libraries (Part 1)
On September 23rd the first Editor’s draft of the Design Tokens specification was released, defining how the design decisions of your system in a platform-agnostic format can be built in order to improve the designer-developer workflow.
There are two important concepts we are going to cover in the following lines: design tool and translation tool. These tools are the two first important pieces of the automation pipeline. The system components are built by re-using the assets and styles stored in the design tool library previously defined by the design team.
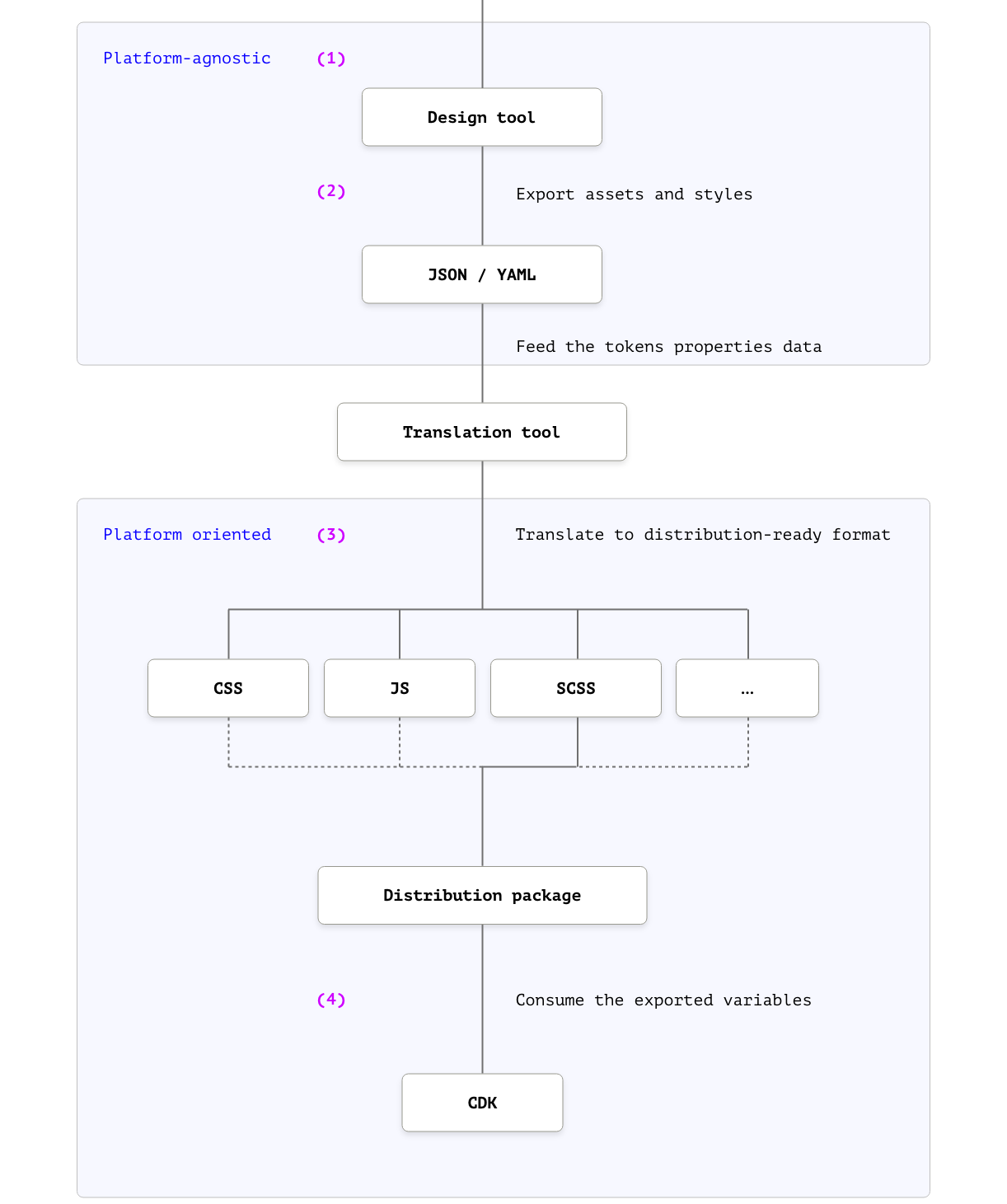
These library assets are the first state of the design tokens of the system, and the ideal journey, until they are consumed by a component library, would be more or less like this:
- Definition of the design decisions in the design tool
- Sync between the design tool and the translation tool
- Translation from platform-agnostic to platform-dependent
- Consume the exported variables in the CDK
Or better visually presented in the following schema:
The kind and the number of design tokens are directly proportional to the complexity of the system and how many decisions the team wants to centralize in order to keep the code and the design in sync.
Let’s put a quick example, we will define a body-medium character style. This style is formed by the following CSS properties:
Some of these CSS properties are going to be reused across other variations of the body styles. For example, body-large will reuse every property unless the font-size.
This is how our body variations look like in our design tool:

Now it’s time to export the design tool’s character styles to a platform-agnostic format.
[1] In this particular schema, the translation tool will export the variables in a .scss format file to be consumed by the component library.
[2] Most typography values in design tools are usually defined in pixels, so based on a root font-size of 16px our body character styles have a line-height of 24px.
From the design tools to the translation tools
For our second step in the journey, we’re only going to cover the integration within Adobe XD and Style-dictionary and a Figma plugin called Design Tokens.
Although some of the processes are fully automated, there are still some of them that need to be done manually when facing the creation of the JSON file.
Adobe DSP
Adobe DSP (Design system package) is a Visual Studio Code integration that allows exporting your design tokens using the configuration of Amazon’s Style-dictionary library underneath.
Although the functionalities have been improved substantially since the earliest versions to the current (v1.2.3), Adobe’s DSP still needs plenty of manual work to create a JSON file with the design tokens a complex system may need.
In the following schema, we can see some examples of the manual vs the automated work needed to invest using DSP.
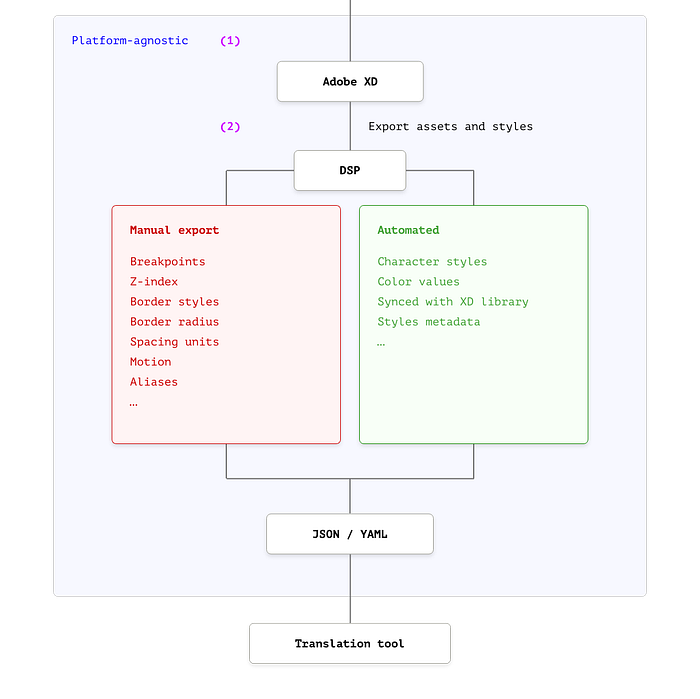
If we come back to our previous body-medium character style, by default the DSP tool only automatically creates the following properties in our fonts-json file³:
body-medium character style (font-family, font-weight, and font-size⁴)These tokens are in sync with our XD library, it means that any change affecting the body-medium character style that has been published will be reflected automatically in our tokens data but, if we want to add more information to our token (e.g. color, line-height, letter-spacing…) we need to do it manually using the DSP interface⁵
[3] If you are interested in how to set up the process to start working with DSP in visual studio check the Adobe documentation.
[4] The font sizes are represented as numeric values in the DSP tool, when coming from the library, the value is represented in pixels, but when exported, relative units are used so: 16px => 16rem.
[5] Demian Borba has written a great article about how to use aliases or include new tokens using the DSP interface.
Working with Figma
One of the most interesting functionalities that Figma provides is the ability to work with their API to extract a JSON file with every layer, object, component, or any style from a file.

Using the example above we can extract our body-medium style metadata from the Figma file where the asset was published.
Although the Figma API is amazingly powerful, there are already open source tools that can handle the workload for us. One interesting example is the Design Token plugin by Lukas Oppermann.
This plugin allows to export the design tokens as a JSON file or to a remote repository using GitHub actions⁶ and apart from the Figma default tokens, it's possible to export the following default plugin custom tokens: border, border-radius, size, spacing, breakpoints and motion. But potentially you can export any property that Figma customization provides.
Exporting directly the JSON file from Figma using this plugin gives us already some advantages in the design tokens automation pipeline. Settled the base of which Figma properties we are going to export as tokens, Style Dictionary will handle the translation of the values (we can always customize this process by editing their config.json file).
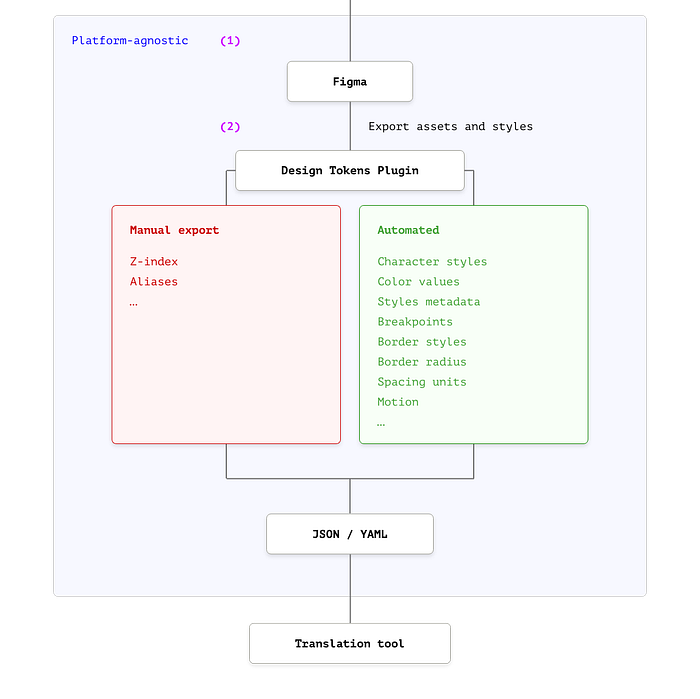
Let’s see now how the JSON file for our body-medium character style looks when exported using the Design Tokens plugin:
body-medium character style.By default, the plugin exported JSON file is giving us more information from our character style. But if we want to use aliases⁷ and reuse some of the CSS property values increasing token granularity, we are in the same position we had with DSP, we need to do it manually:
[6] Documentation about how to send directly the generated JSON to a GitHub repository from theFigma’s Design Tokens plugin window.
[7] In the documentation of Amazon’s Style Dictionary, we can find how to use references (alias) to reuse existing values using the dot-notation object path.
File structure, hierarchy, and naming conventions
Part of the process is to find a way to build our JSON file structure accordingly to our team’s naming conventions and/or mental model⁸.
One of the counterparts of using third-party tooling is that probably we will need to stick to the structure that was defined previously (e.g. DSP has two main JSON files by default in their src: fonts.json and tokens.json ), or in other cases, redefine the structure provided to fit our desired one (e.g. adding custom prefixes to your styles).
It also affects not only the file structure and naming but also how we organize our files:
tokens/
├── color.json
├── font.json
├── border.json
├── shadow.json
├── spacing.json
├── breakpoints.json
└── z-index.jsonWe can decide to have multiple files for our core Design Tokens in order to keep them well organized and readable (as listed above) or have them all together in a tokens.json file.
Defining the file structure, hierarchy and naming is an essential task of the workflow and it can condition the way the pipeline is built.
[8] Example from the Editor’s draft of Design Tokens Format Module about how related tokens can be nested when files are manually authored.
Wrapping up
In this “Part 1”, we covered part of the platform-agnostic area when building a Design Tokens automation pipeline, starting with two of the most widely used design tools in the market. There are plenty of technical details I know there are missing (And probably better ways to set up this pipeline).
The objective rather than giving all the needed information to set up the automation workflow is to provide a holistic picture of how the pipeline looks and how we can reduce the manual workload to keep design and developer teams in sync.
In the second part, we are going to cover the configuration of the translation tool and how to automatically serve the platform-oriented values to a component library and consume them as a dependency.
Stay tuned!
